




Python实现CSDN博客导出Markdown文件并解决防盗链问题
1 前言
因为之前几年的学习笔记,因为个人原因东一块西一块,导致很多都找不到了,遂搭建了一个自己的个人网站,想着用来存储一下日常的学习笔记,还有就是吐吐槽。
网站搭建完成之后突然发现,自己现在能找到的笔记寥寥无几网站内容实在太过挂单无味,而且平时自己看了很多博客收藏了后面总是找不到了,便想着能不能从CSDN白嫖一下,借用一下这个线程的博客库里面的精品博客,哈哈哈。
一开始是打算百度看下有没有现成的工具,没想着自己开发的。但是转了一圈发现……一个能打的都没有,都只是实现了将博客转为Markdown格式的文件下载下来,但是网站防盗链的问题并没有解决,下载下来的Markdown文件引用的网络图片资源和视频资源都没法正常显示,那这有个锤子用啊,你在努努力加几个扩展接口,让我们配置图床或者文件服务器,直接一键解决不好吗……&*&(*())*……
所以不得已,只能自己造轮子了,遂有了现在这个教程,宝子们感动吗?
目前已完成图片资源正常导出,视频资源请稍微等我手头稍微宽裕点,有钱搭建文件服务器再说哈。
2 问题梳理及解决方案
各大主流博客网站大多都有对媒体资源进行防盗处理,比较大方一点的只是给媒体资源加上了水印,咱还能正常的显示,但是大多数的网站的防盗处理都是直接把门焊死,不给其他网站使用。
防盗链这个词指的是做了防盗处理的媒体资源链接,其他网站访问这个链接时,后台程序会校验这个链接的请求端是不是属于该网站的页面,如果不是则拒绝服务或者重定向返回其他资源。这样就会导致我们本地或者服务器上的Markdown文件中的媒体资源无法正常加载。
了解了防盗链,那么我们就有了对应的解决方案。其实也很简单,通过设计者请求header中的Referer属性值为资源所属网站就可以正常加载了。
获取到对应的媒体资源之后,我们需要将媒体资源上传到一个我们的服务器能够正常获取资源的地方,比如各大云服务商的存储服务器,或者自己搭建的存储库。
理论成立,那么实战开始,大家伙跟我一起开干!!!
3 实战演练
3.1 获取博客对应的网页资源
这里请求网页资源用的是requests,不喜欢的小伙伴可以根据自己的喜好选择。
def fetch_html_content(url):
"""
发送 HTTP 请求获取 HTML 内容。
参数:
url (str): 目标 URL。
headers (dict): 请求头。
返回:
str: HTML 内容。
"""
try:
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
})
response.raise_for_status() # 检查请求是否成功
response.encoding = 'utf-8'
return response.text
except requests.RequestException as e:
print(f"请求失败: {e}")
return None
3.2 解析网页资源中的Markdown博客信息
获取到网页资源后,我们需要进行解析,将Markdown部分提取出来,并且将我们不需要的部分信息去除,比如下面这些信息就是我不需要的,所以需要去除。

解析html我用的是BeautifulSoup,通过blog-content-box属性获取博客内容,并将里面的无关元素去除。
def parse_html(html_content):
"""
解析 HTML 内容,提取文章主体和标题。
参数:
html_content (str): HTML 内容。
返回:
tuple: (文章主体内容, 文章标题)。
"""
soup = BeautifulSoup(html_content, 'html.parser')
body_content = soup.find('div', class_='blog-content-box')
# 去除不必要的元素
for element in soup.find_all(class_='article-info-box'):
element.decompose()
soup.find(id='blogHuaweiyunAdvert').decompose()
soup.find(id='blogColumnPayAdvert').decompose()
title = soup.find('h1', id='articleContentId')
if body_content and title:
return str(body_content), title.text.strip()
else:
print("未能找到文章主体或标题")
return None, None
3.3 将Html内容转换为Markdown格式
这里用到的是markdownify模块,markdownify 是一个将 HTML 转换为 Markdown 格式的工具或库。Markdown 是一种轻量级的标记语言,用于通过纯文本格式快速生成格式化的内容(例如标题、列表、链接等),并且可以转换为 HTML。markdownify 的作用就是将 HTML 内容转换为 Markdown 格式,以便更方便地在需要 Markdown 格式的地方使用,例如在 GitHub 或某些博客平台中。
def convert_to_markdown(body_content):
"""
将 HTML 内容转换为 Markdown。
参数:
body_content (str): HTML 内容。
返回:
str: Markdown 内容。
"""
return md(body_content)
3.4 从Markdown中提取媒体资源
3.4.1 获取资源url
获取到的Markdown文本之后,我们需要从中提取媒体链接,后续下载需要用到。
def extract_image_urls(markdown_text):
"""
从 Markdown 文本中提取图片 URL。
参数:
markdown_text (str): Markdown 文本。
返回:
list: 图片 URL 列表。
"""
pattern = r'!\[.*?\]\((.*?)\)'
image_urls = re.findall(pattern, markdown_text)
return image_urls
3.4.2 下载资源到本地
def download_images(source_url, image_urls, save_dir):
"""
下载图片并保存到指定目录。
参数:
:image_urls (list): 图片 URL 列表。
save_dir (str): 保存目录。
:type source_url: 源数据Url
"""
if not os.path.exists(save_dir):
os.makedirs(save_dir)
img_list = []
for url in image_urls:
# 如果不是图片文件,跳过
if not is_image_file(url):
continue
try:
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': source_url
})
response.raise_for_status()
filename = os.path.join(save_dir, os.path.basename(url))
with open(filename, 'wb') as f:
f.write(response.content)
print(f"图片 {filename} 下载成功")
img_list.append({'url': url, 'path': filename})
except requests.RequestException as e:
print(f"图片下载失败: {e}")
return img_list
3.5 将资源文件上传到一个你能去的地方
这里我是用了自己搭建的图床作为资源提供商,后续Markdown文件将从这个图床获取图片资源。有条件的可以自己搭建一个文件服务器,比如Fast DFS,这样就用和我一样只支持图片资源了。
这里推荐一下我用的开源图床:简单图床,真的很简单!还支持了PicGo,本地Typora可以配合PicGo+简单图床直接完成本地图片的上传,不用一张一张替换图片地址!!!同时还有对应的使用手册。
def upload_image(url, image_path, token):
"""
上传图片到简单图床2.0的方法
:param url 上传接口
:param image_path: 图片文件的本地路径
:param token: 请求的 token(如示例中的 token)
:return: API 响应的 JSON 数据
"""
# 创建表单数据
form_data = {
'token': token,
}
# 读取图片文件
with open(image_path, 'rb') as image_file:
files = {
'image': (image_path.split('/')[-1], image_file, 'image/jpeg') # 假设图片是 JPEG 格式,按需修改
}
# 发送 POST 请求,上传图片
try:
response = requests.post(url, data=form_data, files=files)
response.raise_for_status() # 如果响应代码不是 2xx 会抛出异常
return response.json() # 返回 API 响应的 JSON 数据
except requests.exceptions.RequestException as e:
print(f"上传图片时出错: {e}")
return {'error': str(e)}
3.6 将Markdown中的资源指向它能去的地方
# 替换图片链接
for img in img_list:
markdown_content = markdown_content.replace(img['url'], img['target_url'])
# 保存 Markdown 内容到文件
save_markdown_to_file(title, markdown_content)
4 完整源码
完成以上几步后,恭喜大家,我们已经完成了Markdown网络资源的替换,我们Markdown中的资源终于可以正常加载了!!!
下面放下我的完整源码,里面我还做了图片的压缩和完成导出工作后的资源清理。
import os
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify as md
import re
from PIL import Image
import glob
def fetch_html_content(url):
"""
发送 HTTP 请求获取 HTML 内容。
参数:
url (str): 目标 URL。
headers (dict): 请求头。
返回:
str: HTML 内容。
"""
try:
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
})
response.raise_for_status() # 检查请求是否成功
response.encoding = 'utf-8'
return response.text
except requests.RequestException as e:
print(f"请求失败: {e}")
return None
def parse_html(html_content):
"""
解析 HTML 内容,提取文章主体和标题。
参数:
html_content (str): HTML 内容。
返回:
tuple: (文章主体内容, 文章标题)。
"""
soup = BeautifulSoup(html_content, 'html.parser')
body_content = soup.find('div', class_='blog-content-box')
# 去除不必要的元素
for element in soup.find_all(class_='article-info-box'):
element.decompose()
soup.find(id='blogHuaweiyunAdvert').decompose()
soup.find(id='blogColumnPayAdvert').decompose()
title = soup.find('h1', id='articleContentId')
if body_content and title:
return str(body_content), title.text.strip()
else:
print("未能找到文章主体或标题")
return None, None
def convert_to_markdown(body_content):
"""
将 HTML 内容转换为 Markdown。
参数:
body_content (str): HTML 内容。
返回:
str: Markdown 内容。
"""
return md(body_content)
def extract_image_urls(markdown_text):
"""
从 Markdown 文本中提取图片 URL。
参数:
markdown_text (str): Markdown 文本。
返回:
list: 图片 URL 列表。
"""
pattern = r'!\[.*?\]\((.*?)\)'
image_urls = re.findall(pattern, markdown_text)
return image_urls
def is_image_file(s):
# 定义常见的图片扩展名
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp', '.svg', '.ico'}
# 找到最后一个 '.' 的位置
dot_index = s.rfind('.')
# 如果存在扩展名并且是图片格式
if dot_index != -1:
extension = s[dot_index:].lower() # 获取扩展名并转化为小写
if extension in image_extensions:
return True # 如果是图片格式,返回 True
return False # 如果没有扩展名或不是图片格式,返回 False
def download_images(source_url, image_urls, save_dir):
"""
下载图片并保存到指定目录。
参数:
:image_urls (list): 图片 URL 列表。
save_dir (str): 保存目录。
:type source_url: 源数据Url
"""
if not os.path.exists(save_dir):
os.makedirs(save_dir)
img_list = []
for url in image_urls:
# 如果不是图片文件,跳过
if not is_image_file(url):
continue
try:
response = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': source_url
})
response.raise_for_status()
filename = os.path.join(save_dir, os.path.basename(url))
with open(filename, 'wb') as f:
f.write(response.content)
print(f"图片 {filename} 下载成功")
img_list.append({'url': url, 'path': filename})
except requests.RequestException as e:
print(f"图片下载失败: {e}")
return img_list
def save_markdown_to_file(title, markdown_content):
"""
将 Markdown 内容保存到文件。
参数:
title (str): 文件名。
markdown_content (str): Markdown 内容。
"""
try:
with open(f'{title}.md', 'w', encoding='utf-8') as f:
f.write(markdown_content)
print(f"文件 {title}.md 保存成功")
except IOError as e:
print(f"文件保存失败: {e}")
def upload_image(url, image_path, token):
"""
上传图片到简单图床2.0的方法
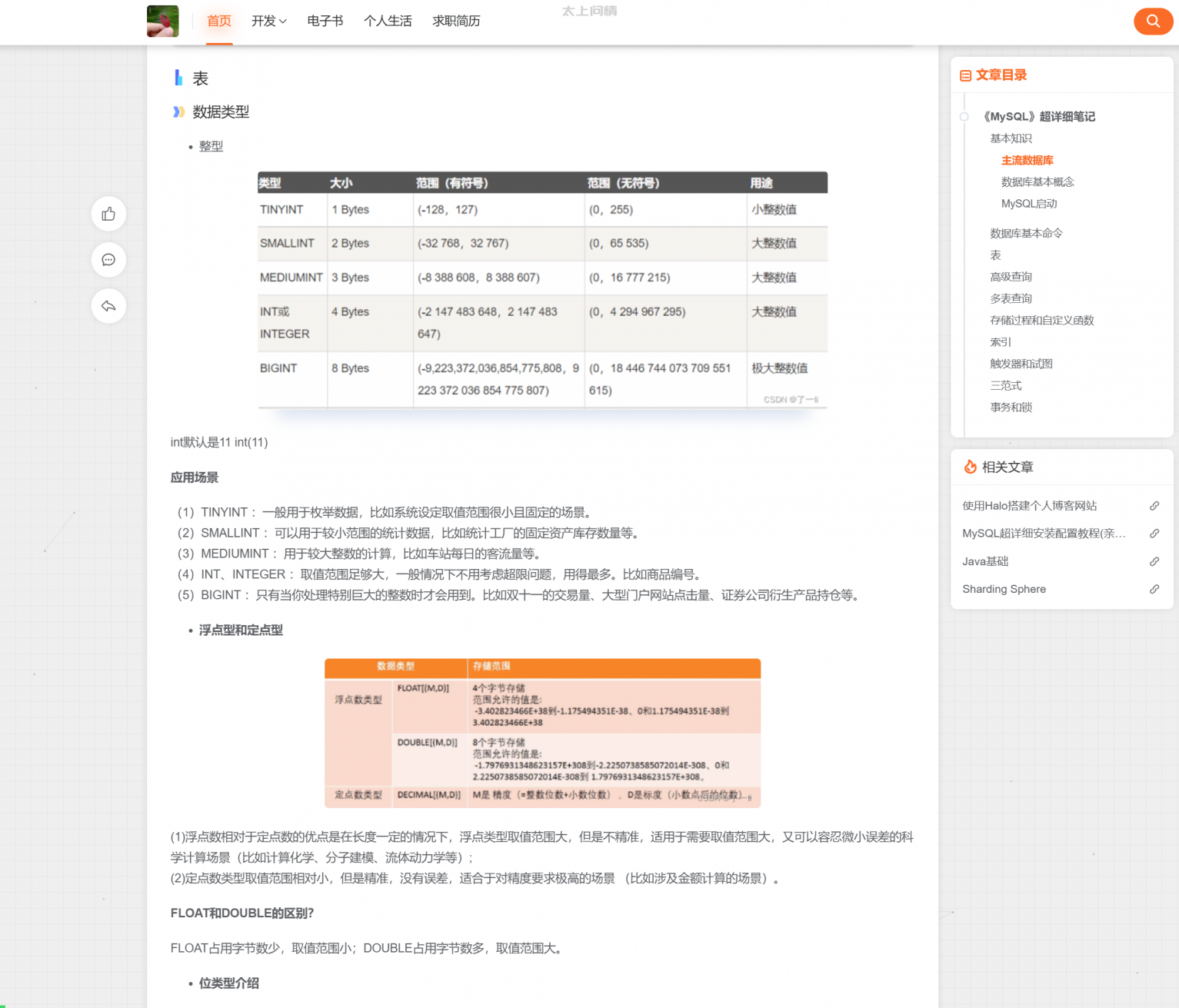
:param url 上传接口
:param image_path: 图片文件的本地路径
:param token: 请求的 token(如示例中的 token)
:return: API 响应的 JSON 数据
"""
# 创建表单数据
form_data = {
'token': token,
}
# 读取图片文件
with open(image_path, 'rb') as image_file:
files = {
'image': (image_path.split('/')[-1], image_file, 'image/jpeg') # 假设图片是 JPEG 格式,按需修改
}
# 发送 POST 请求,上传图片
try:
response = requests.post(url, data=form_data, files=files)
response.raise_for_status() # 如果响应代码不是 2xx 会抛出异常
return response.json() # 返回 API 响应的 JSON 数据
except requests.exceptions.RequestException as e:
print(f"上传图片时出错: {e}")
return {'error': str(e)}
def compress_image(input_path, max_size_mb):
"""
压缩图片体积,如果图片体积小于指定的最大体积,则不压缩;如果大于指定的最大体积,则压缩到指定的最大体积。
参数:
input_path (str): 输入图片路径。
max_size_mb (float): 最大文件体积(单位:MB)。
返回:
None
"""
# 将最大体积从 MB 转换为 KB
max_size_kb = max_size_mb * 1024
# 获取输入图片的文件大小
input_size_kb = os.path.getsize(input_path) / 1024
# 如果图片体积小于或等于最大体积,不进行压缩
if input_size_kb <= max_size_kb:
print(f"图片体积已小于或等于 {max_size_mb} MB,无需压缩")
return
# 打开图片
with Image.open(input_path) as img:
# 初始质量设为 95
quality = 95
while True:
# 保存压缩后的图片到原路径
img.save(input_path, optimize=True, quality=quality)
# 获取压缩后的图片文件大小
output_size_kb = os.path.getsize(input_path) / 1024
# 如果压缩后的图片体积小于或等于最大体积,退出循环
if output_size_kb <= max_size_kb:
break
# 调整质量,继续压缩
quality -= 5
# 如果质量降到 10 以下,停止压缩
if quality < 10:
print("无法进一步压缩图片以达到指定体积")
break
print(f"图片已压缩到 {output_size_kb / 1024:.2f} MB,保存到 {input_path}")
def get_file_paths(directory, pattern='*'):
"""
读取指定文件夹中的文件路径。
参数:
directory (str): 文件夹路径。
pattern (str, optional): 文件匹配模式,默认为 '*'(匹配所有文件)。
返回:
list: 包含文件路径的列表。
"""
# 构建完整的文件路径模式
full_pattern = os.path.join(directory, pattern)
# 使用 glob 模块获取匹配的文件路径
file_paths = glob.glob(full_pattern)
return file_paths
def main(source_url, upload_url, token):
# 获取 HTML 内容
html_content = fetch_html_content(source_url)
if not html_content:
return
# 解析 HTML 内容
body_content, title = parse_html(html_content)
if not body_content or not title:
return
# 转换为 Markdown
markdown_content = convert_to_markdown(body_content)
# 提取图片链接
img_links = extract_image_urls(markdown_content)
# 下载图片
img_list = download_images(source_url, img_links, f"images")
all_upload_success = True
for img in img_list:
path = img['path']
# 压缩图片大小到1M以内
compress_image(path, 1)
# 上传图片
res = upload_image(upload_url, path, token)
if res['code'] == 200:
img['target_url'] = res['url']
print(f"图片上传成功,URL: {res['url']}")
else:
print(f"图片上传失败,错误信息: {res['message']}")
all_upload_success = False
break
if all_upload_success:
# 替换图片链接
for img in img_list:
markdown_content = markdown_content.replace(img['url'], img['target_url'])
# 保存 Markdown 内容到文件
save_markdown_to_file(title, markdown_content)
# 删除所有 images 目录下的文件
file_paths = get_file_paths('images')
for file_path in file_paths:
os.remove(file_path)
if __name__ == '__main__':
# 常量定义
upload_url = 'http://xxxxx/api/index.php'
token = 'xxxxxxxxxxx'
# 获取字符串输入
source_url = input("请输入CSND博文地址: ")
main(source_url, upload_url, token)
5 成果展示
好了,完结撒花,睡觉,一不小心都凌晨一点了!!!
评论区